Testing and Training
Generally split the data randomly into
- 80% for training
- 20% for testing
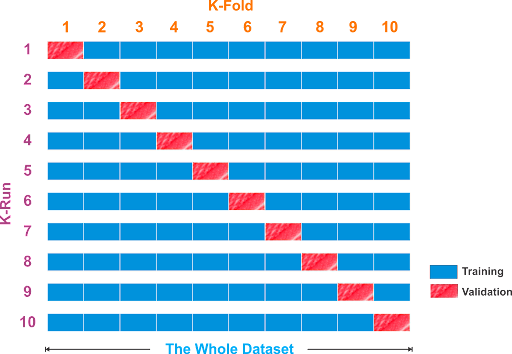
K-Fold Cross Validation
K-Fold Cross Validation
Warning
Don’t use this if you only have a little data
- Cut the data into chunks
- Make splits. In each, use one chunk for testing and the other chunks for training
- Train on those, report test accuracy
Link to original
Leave One Out Cross Validation
Warning
This is computationally expensive, so prefer K-Fold Cross Validation
- Only use when every ounce of training data counts
- Will let you see exactly where your algorithm falls down
Validation Sets
One possible problem is that you overfit instead of the model overfitting
- You might tune the hyperparameters to fit the test data too well
- Now info about test set has been propagated back to algorithm
Solution: Split into training, test, and validation set
Validation data can be used to tune hyperparameters for your model, then testing data is used at the end to evaluate accuracy
Most people don’t actually do this because it’s too much work
Training Failures
Main reasons for model not working:
- Overfitting
- Unable to generalize
- Cues in on patterns in training data that don’t actually exist in real world
- Can think of a decision tree with way too many nodes/rules
- Kinda like superstitions
- Underfitting
- Too general
- Can think of a decision tree with only a couple levels
- Lack of model power
- Some patterns are just too complicated for, say, decision trees
- Lack of signal in data
- It really is impossible to learn anything from the data
Combating Training Failures
Overfitting
Decision trees have a really bad overfitting problem, can deal with it by:
- Applying a depth limit where we chop everything off after 4 levels
- Depth limit is a hyperparameter for decision trees
- Trying different ones and see how it affects our accuracy on the test set
Play around with a bunch of hyperparameters and see what works best for the test set
Evaluation
Accuracy
Easiest way to see how model is doing is accuracy
Class Imbalance
But class imbalance is a problem
Happens when an overwhelming majority of your data is a single class
Examples of class imbalance:
- Fraud - Most transactions aren’t fraudulent
- Disease - Most people won’t have the disease
- Product - Most people won’t buy any given product
It’s very common to have a rare positive signal surrounded by negatives
Confusion Matrix
Shows you true positives, false positives, true negatives, and false negatives
| Positive | Negative | |
|---|---|---|
| Classified Positive | True positive% | False positive% |
| Classified Negative | False negative% | True negative% |
Precision
Precision is how many of the things that we classified as positive were actually positive
Use precision when we only care about being correct about the things we identify as positive, e.g., Google doesn’t care if it turns away 1000 good engineers, they only care if the ones it does hire are good
Recall
Recall is how many of our positive class we didn’t miss
Use recall when we want to make sure we don’t miss anything, e.g., identifying people with disease
Confidence
Most ML algorithms can tell you how confident they are in an answer
Depending on use case, you may want to take the confidence into account, e.g., launching nukes
Log loss: A measure of accuracy that penalizes overconfidence
F1 score
Harmonic mean of precision and recall, used when both are important
Warning
Max thinks this is an awful metric